When ML Meets LC–MS/MS: Generalization Gaps in Small-Molecule Identification
TL;DR Summary
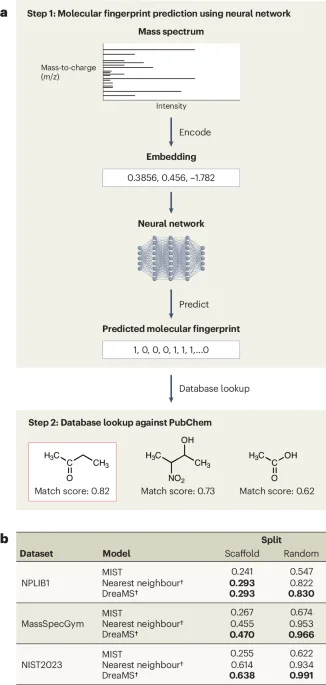
ML models for small-molecule structure elucidation from LC–MS/MS perform poorly compared with simple baselines due to generalization gaps across experimental conditions, ignored peak intensities, and unseen fragment formulas. Scaffold-split evaluations show nearest-neighbor retrieval often outperforms top models like MIST and DreaMS, revealing weak real-world generalization. Data-attribution analyses indicate the problems arise from both data and model design, prompting calls for domain-aware architectures, standardized datasets, and benchmarks that move beyond fingerprint-based, NLP-inspired translation toward chemistry-informed approaches.
Topics:science#generalization#machine-learning#mass-spectrometry#metabolomics#note-only-five-tags-requested#structure-elucidation#technology
Reading Insights
Total Reads
0
Unique Readers
4
Time Saved
10 min
vs 11 min read
Condensed
96%
2,067 → 75 words
Want the full story? Read the original article
Read on Nature