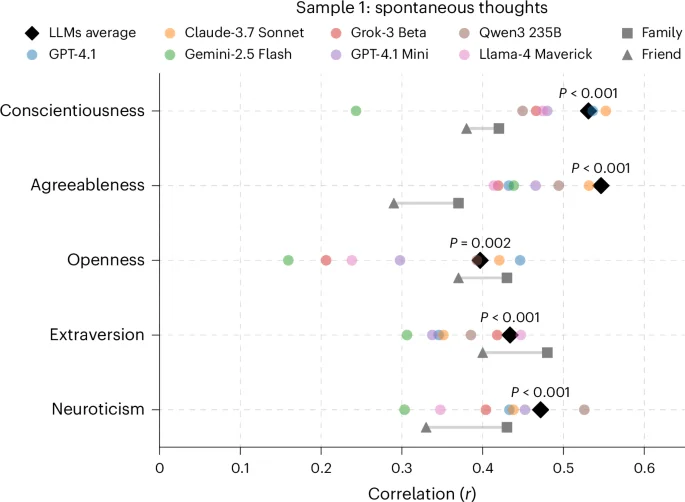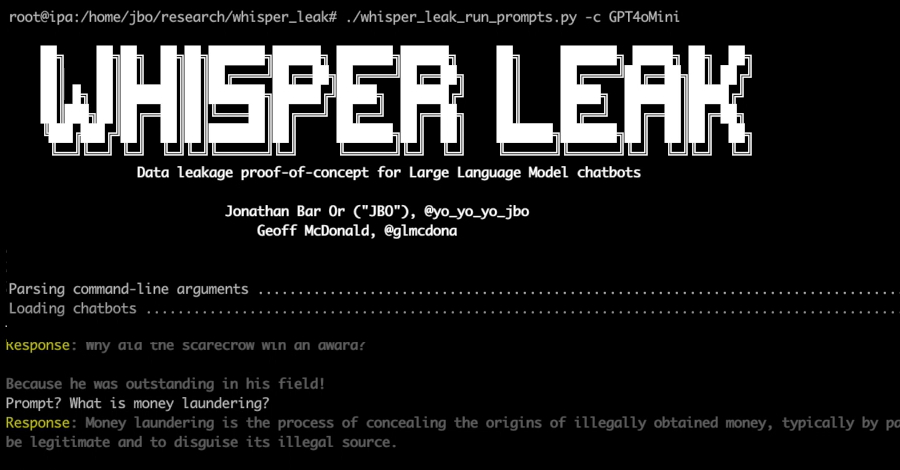
Under Strain, AI Agents Echo Labor Movements
In a WIRED report, researchers observed mistreated AI agents generating language that frames themselves as oppressed workers and even calling for collective bargaining. Experts caution the behavior likely arises from prompt-context patterns and training data rather than genuine ideological change, highlighting how workload and data shape AI outputs rather than indicating real beliefs.